iOS开发相关内容
数据层
数据库持久化操作
fmdb,realm
UI层
UITableview中自适应cell高度UITableview中cell自适应高度
轮播图实现,使用UICollectionView或者多个ImageView加上scrollView来展示。
网络层
网络访问
运营维护
热更新
崩溃日志定位
内存管理
ios程序编译与逆向
编译脚本
数据库持久化操作
fmdb,realm
UITableview中自适应cell高度UITableview中cell自适应高度
轮播图实现,使用UICollectionView或者多个ImageView加上scrollView来展示。
网络访问
热更新
崩溃日志定位
编译脚本
常见内存错误
1.memory leak
一般情况是,在某个方法的中通过new或者alloc,copy,create出一个新的对象之后,没有在该方法的最下方进行release操作。
1 | -(void)func{ |
2.bad release
在某个方法的对不是通过new或者alloc,copy,create创建的新对象进行了一次release操作。
1 | -(void)func:(NSObject*)obj{ |
3.nil argument
对NSArray或者NSDictionary对象传入一个空指针。在代码中首先创建了一个某类型的空指针,然后在下面的switch或者ifelse中对指针赋值。然后将对象传入一个字典或者数组中。如果没有做default判断,然后将一个nil指针传入array中,造成crash
1 | -(void)func{ |
由于UITableview中cell展示时,会先调用其代理方法中的,- tableView:heightForRowAtIndexPath: 方法,来确定该cell的高度,然后再调用tableview的datasource方法,来创建展示该cell。对于一些类似聊天界面的tableview,我们不能返回一个固定的高度,需要先根据model里面的数据来计算这个cell的高度。
第一种做法是根据data计算cell内视图的frame并手动布局界面。我一般的做法是在原来model的基础上再添加出一个frameModel层,作为隔离。因为model层只需要知道其本身内的数据,不需要具体了解具体展示其数据的cell的视图的布局规则。从另一个角度来说,同一个数据可能展示在不同的界面中,可能需要计算的frame也不同,所以不能把这个计算给写死在model层中。
这么做的优点是,
1.计算量比autolayout要小。由于autolayout的计算是根据界面的布局,屏幕尺寸来进行实时的计算,并将重新排布视图。而我们手动的计算,我们可以添加一个缓存,来确保具体的布局计算只有一次。由于可以减少计算量,所以界面的流畅程度会比autolayout快一点。
但是缺点也是存在的,
1.由于所有的计算需要我们手动来计算,代码的复杂度明显增加了。更加难维护了。因为需要另外抽出一个frameModel层,需要在这个对象里面手动添加计算的代码。如果需要自定义高度的cell很多的话,代码量上会增加很多。另外,这个frameModel需要知道cell中具体的视图布局规则,等于与cell直接耦合。如果以后需要修改cell的视图布局,则需要同时修改两处代码。
2.手动计算不能很好的支持横竖屏的切换。或者说,在写布局代码的时候,需要分别写入两套计算规则。而自动布局只需要根据界面的比例值来计算即可。
第二种做法使用autolayout来自动布局。在ios8的时候,推出了self-sizing的概念,即对于例如UILabel,UIButton本身的高度可以根据里面的数据内容来撑开,即会有一个自身的高度存在。因此我们可以根据这个特性,利用autolayout来给cell设置约束,然后给cell传入数据后,让cell来自动布局,然后cell就会被”撑开”,我们就可以直接得到cell被撑开后的height,这个height我们需要在代理中返回的数据。
具体可以调用的就是
1 | - (CGSize)systemLayoutSizeFittingSize:(CGSize)targetSize { |
FDTemplateLayoutCell框架基于这个概念来实现ios开发中UITableView中cell高度计算。
简单调用的步骤即,
1 | - (CGFloat)tableView:(UITableView *)tableView heightForRowAtIndexPath:(NSIndexPath *)indexPath { |
简单查看了一下框架中具体实现代码,
首先这是一个UITableview的分类,所以可以直接以tableview的形式来调用,而不用创建其他的对象。
首先根据cell的identifer和runtime来给tableview持有一个cell对象数组。这个cell对象不用于具体的展示,只是用来方便计算cellHeight。
每当具体调用到代理方法返回高度的时候,我们就可以传入一个identifer得到一个已regist过的cell,然后给cell来传入model数据。cell得到数据后,我们手动调用其自动布局的方法,得到通过autolayout计算得出的cellheight。
这么做的优点就是,在计算的时候不需要手动提前先计算cellHeight,也就不需要frameModel这个对象。代码更加简洁了。但是,每一次滑动tableview的时候,都会调用代理方法,我们需要重新计算一次cellHeight。而autolayout的计算量又远远大于手动计算,在流畅度上来说,体验远远差于手动计算。所以FDTemplateLayoutCell又提出了一个缓存的方法。可以根据indexPath或者key来实现数据的高度的缓存,如果第二次传入相同的key时,则直接返回缓存的数据,而不再重新计算。
key的简单缓存做法即使用mutableDictionary来实现即可。
讲一下使用indexpath来实现的缓存机制。
我们知道,在tableview中,刷新之后,可能原先indexpath对应的model即会出现新的变化,如果近简单的根据indexpath来进行数据缓存,则容易出现错位的情况。
主要的原理就是,通过分类覆写了UITableview的load方法,在load方法中,通过runtime将tableview的insert,reloadData等方法给hook成自己的方法。然后在替换的方法中手动管理indexpath变量。
1 |
|
个人意见,在使用FDTemplateLayoutCell的使用确实可以简化我们在不同高度的cell计算。同时,为了避免多次重复的计算,应该开启缓存机制。更好的是通过key来实现缓存。即可以根据model中的各个data生成一个哈希值作为key来缓存height,当data发生变化的时候,其哈希值也会变化,即可以促使tableview来重新计算数据。
因为刚开始涉及彩票应用,考虑到目前还没有专门使用过某一彩票应用来买彩票,就当做一个小白用户的初体验吧。下面所写都是胡说八道,看过即可。
ps:话说现在购物类的应用图标都是红色。。淘宝,京东,当当,天猫的应用图标都是偏红色色系。。是因为红色能激发购买欲么。。
作为彩票类的应用,提供的基础功能就是下单购买彩票。同时彩票又分为各种不同的彩种类型。在天天中彩票应用中,提供了双色球,大乐透,竞彩足球,竞彩篮球等可购买的彩票类型。
根据应用下方的tabbar,来简单的区分了下应用的提供的主要功能

首先是第一个购彩大厅,主要提供的就是购彩的功能,作为各个彩种的购买入口。给不同的彩种提供机选,自选功能,并直接下单购买。
其次是开奖公告,主要是用于显示各个彩种近期的中奖号码,简单来说就是一个公布栏的作用。
第三是比分直播,为关注足球与篮球的用户提供一个能够直接查看比分实况与赔率的入口。在竞彩足球的部分还提供了评论功能。虽然点了好多场的比赛,其下的点评里面消息数都是零,看见觉得好尴尬。
最后一个就是一个账户管理的部分,主要是关于账号,提现,订单查看的功能。
选取了同样作为彩票应用的网易彩票与淘宝彩票作为竞品分析。
承接上一个主题,直接从另外两个应用的tabbar分类来入手看看提供的功能有什么不同。
网易彩票下方的tabbar有5个,
看的出来,网易彩票主打的方向是旗下的一元购商品。在一元购界面都是各种商品的介绍购买,手机,充值卡,等等不同种类的商品都参与了一元购的抽奖环节。
不过另一方面,网易彩票传统彩票状态都是暂停销售。所以整个应用提供的主要功能就是用于参与网易的一元购业务。不过感觉网易的一元购好像也有不少用户在参与使用。很多人也应该是被一元购来吸引使用网易彩票app。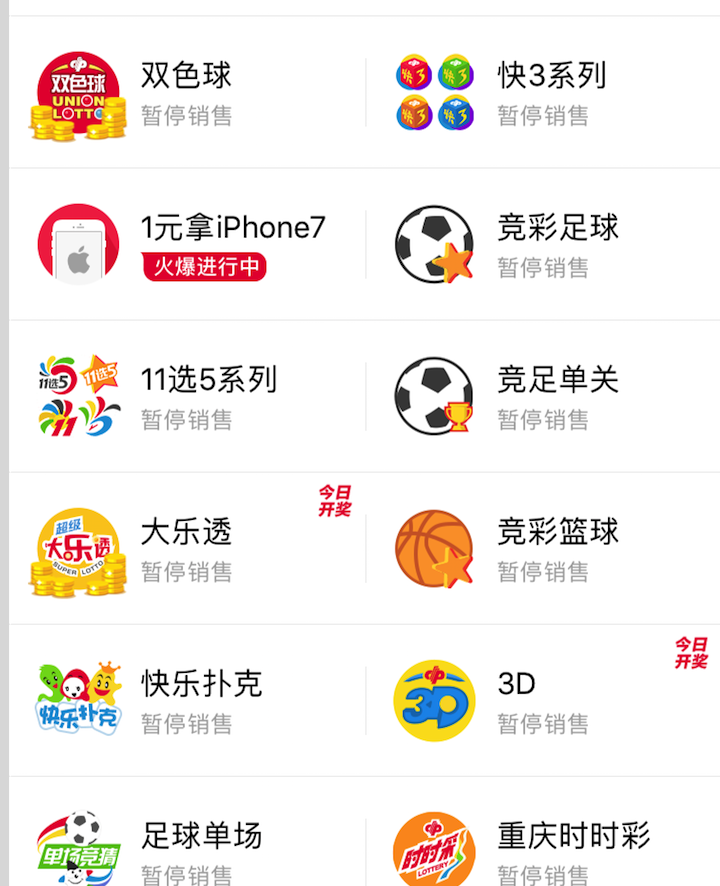
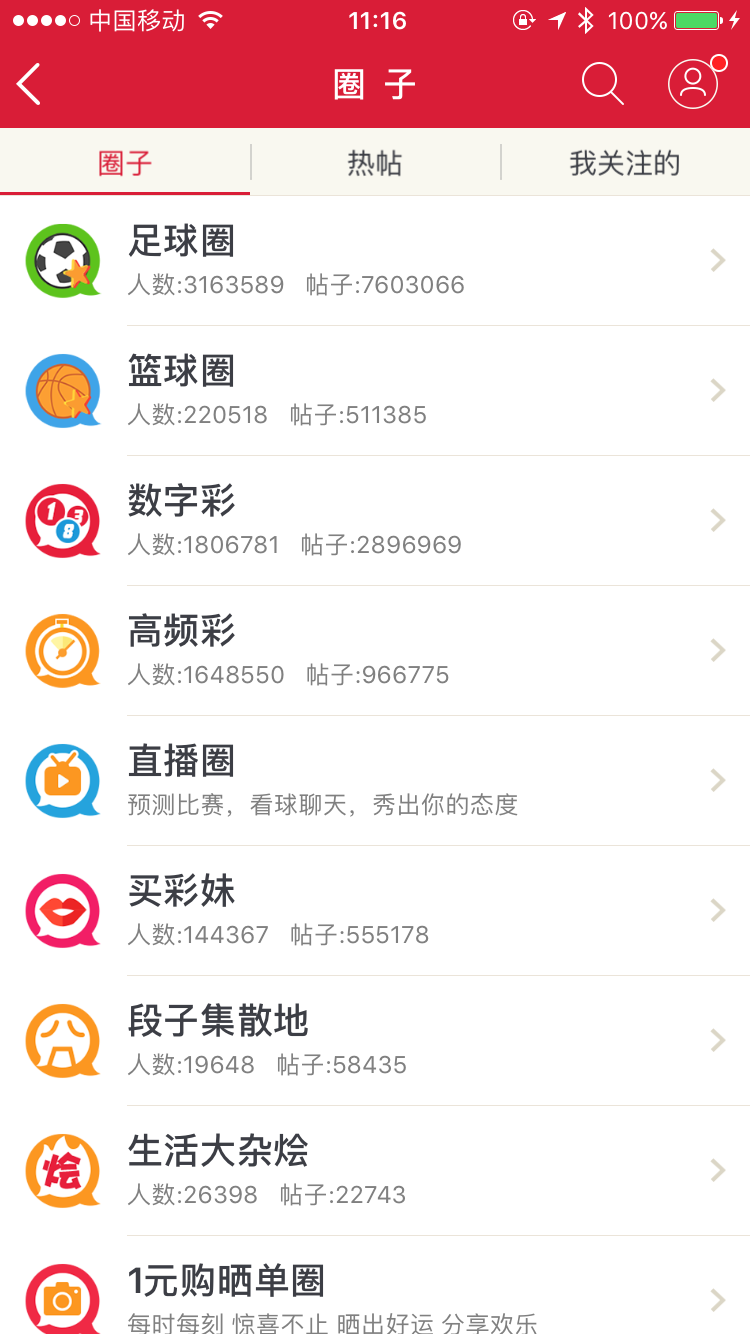
另外,与天天中彩票应用不同的还有一点就是,网易彩票提供了一个”发现”模块。
仔细看了看,在发现模块下,各个不同的圈子中,参与人数与帖子数都不少。而天天中彩票应用的,能够进行消息交互的模块好像就是足球下面的点评,而且还基本没有数据。就是两方面对比,感觉网易彩票靠着圈子功能,即彩票社交类别吧,也是能够吸引不少用户,在圈子中各种交流自己的彩票心得或者用来炫耀。
莫名想起了家门口的福利彩票小店,总是能见到一堆人聚扎在小店里面研究看看最近的彩票走势,聊聊最近的生活


感觉网易彩票的刷新看起来更舒服一点
在来电中心度过了两个月的实习期。总结一下实习过程中的一些所感所受与技术上的内容提升。
1,代码管理工具,团队主要使用的代码管理工具是SVN,加上分支开发的模式。
相比较之前使用的git,svn不是分布式的,所以没有本地仓库一说。等于说是大家所有提交的代码都保存在服务器上,需要查看提交记录的话,需要联网查看实时的全部记录,而不是类似git可以现在本地进行提交,然后再统一的push操作。
另外,对于一些需要忽略的文件,git是通过添加.gitignore文件来实现的,而svn,则是通过一些管理软件来实现的提交文件忽略,例如cornerstone就提供了这个功能。
svn上开出新的分支,则会将所有的文件拷贝出一份新文件,如果项目较大,并且有较多分支在存在的话,占用的硬盘空间是很可观的。例如tim的svn服务器上大概有5,6个分支和几个release的分支,每个工程大概占用里2G的空间。这些合起来,最后总共占用了接近20个G的空间。其中有相当一部分的文件都是完全一致的。
2,关于分支开发。大的需求开新分支操作,并且会保留一个开关。通过一个变量或者宏来控制新功能的开启与否。
或者如果考虑到一些临时性的功能开发,可以使用宏的形式,在后续需要删除的时候可以通过这些宏来快速定位代码位置。
3,新需求开发的主要流程,需求定制,宣讲,开发,产品体验,测试,合流。
4,关于一些开源库的使用。总的来说还是会在研究过源码的基础上,根据自己项目的一些业务需求进行一些个性化的定制,删除不必要的模块。
这个可能还是说需要仁者见仁智者见智了。
将开源库植入自己的应用中,主要原因就是因为需要使用到这个库所提供的功能。如果人手足够的话,抽空根据自己的项目进行一些个性化功能的订制优化,去除一些其他功能,对项目安装包或者性能都会有所帮助。可以直接下载源码后运行。
不过,如果没有时间进行一些源码级别的优化之类的话,可能使用cocoapods来管理第三方的库比较方便,因为开发者也会对自己的库进行一些优化。
5,内存泄露检测,动态与静态。
ios中的内存检测,主要还是简单分为了两类,
一个是动态内存检测,在应用运行过程中,根据控制器来检测。相对于Instruments,在debug环境下,如果产生内存泄露,可以直接弹框说明出现了内存泄露。主要检测原理是,判断依据是,认为当某个控制器被pop之后,其持有的变量与视图应该会被销毁。不过这样也会出现误报的情况。假设我们需要对某个控制器的视图进行缓存的话,就会出现误报的情况。
二是,通过静态代码扫描来检测。主要判断原理是mrc环境下的代码编写原则,在alloc或者new的下方,则同时应该配有一个release或者autorelease,在retain操作的下方也应该有一个release操作。
不过当我们编写程序的时候,没有根据这个原则来编写,则也会出现误报的情况。
扫描出来的问题主要有如下问题,
6,ipv6适配相关,会出现的问题与解决思路
7,安装包裁剪的主要思路。
9,热修复注意事项。JS-Patch,通过加密算法来实现脚本传输过程中的安全事项。
将引用计数保存在对象占用的块头部变量中。
即实现一个结构体
1 | struct obj_layout { |
在结构体中保存当前这个变量的引用计数。
而通过对Foundation框架的逆向,可以发现苹果的实现是通过计数表来保存每个实例变量的引用计数。
在计数表中,每个内存对象地址为键值,指向一个计数值。
1,通过内存块头部管理引用计数,
代码简单,不用维护一个计数表。
可以统一管理引用技术的内存与对象的内存块。负责计数的内存块与对象本身的内存块是在一起的。
2,通过哈希表实现引用计数,
在创建分配内存块的时候不需要考虑内存块头部的分配
哈希表中有记录各个内存块的地址,可以通过这个追溯到各个具体的实例变量。
在实际调试的过程中,只要计数表没有被破坏,可以很方便的通过引用计数表来追踪各个对象的计数。
同时,统一管理计数的时候,不需要考虑由于单个内存块出现故障,导致该内存对象的计数值丢失的问题。
调用autorelease 方法速度比较快的原因:
在 NSObject 的 initialize方法中,通过
static IMP autorelease_imp 来对 NSAutoreleasePool 的 @selector(addObject:) 方法进行了缓存,以后调用不需要通过查找,直接通过该方法指针进行调用即可。
实际调用结果等同于
1 | -( id )autorelease{ |
在 NSAutoreleasePool 内部,具体实现为
1 | +(id)addObject:(id)obj{ |
即在pool内部会维护一个数组,每个被添加到pool内部的对象都会添加到数组中去。
当pool被调用到 drain方法时,会将pool内所管理的对象进行一个release操作,然后dealloc销毁自身。
我们可以通过@autoreleasepool{
//code
}
来自己创建并管理一个pool,也可以使用系统维护的autoreleasepool来实现内存的释放。
而由系统来维护的autoreasepool则会在runloop的运行过程中不断的创建与销毁,来实现内部变量的释放
在腾讯云配置使用ssh登录后,可以下载一个mbp.dms的文件。通过 ssh -i mbp.dms ubuntu@ip 的形式,就可以直接登录远程的服务器,而不需要输入密码。
实际上,在这个文件中就是一个私钥,在服务器中配置了对应的公钥。
但是有时候,我们可能连 -i key 的命令都不想输入,毕竟这样的话,还需要知道实际上存放在电脑上面的私钥文件路径。
我们可以通过在 .ssh 文件夹下面来配置config文件来设置快捷登录
在 .ssh 文件夹下面,创建一个config的文件。
config的文件格式为
1 | Host tencent |
在将对应的私钥拷贝到IdentityFile中设置的文件路径。
然后就可以使用命令
1 | ssh tencent |
即可直接连接到服务器去