RunLoop
简述
runloop用来处理输入各种事项,例如鼠标,键盘事件,NSPort对象,NSConnection 对象,NSTimer对象。所有的触发事件,网络请求,异步回调等等
开发者不能主动创建或者管理runloop,每个线程会主动创建一个runloop对象,如果需要调用runloop,需要使用currentRunloop获取即可。
默认是每个线程具有一个runloop,但是不一定会被创建,当调用currentrunloop方法时,如果没有runloop对象,则会自动创建该对象。
线程和 RunLoop 之间是一一对应的,其关系是保存在一个全局的 Dictionary 里。线程刚创建时并没有 RunLoop,如果你不主动获取,那它一直都不会有。RunLoop 的创建是发生在第一次获取时,RunLoop 的销毁是发生在线程结束时。你只能在一个线程的内部获取其 RunLoop(主线程除外)。
NSURLConnectionLoader 这个线程内部会使用 RunLoop 来接收底层 socket 的事件,并通过之前添加的 Source0 通知到上层的 Delegate。
NSRunLoop 线程不安全
由于nstimer对象并不被认为是input Source,在等待方法回调的时候可能会触发多次调用。
NSRunloop并不是线程安全的,并且runloop相关的方法,只能在runloop所在线程调用,永远不要再其他线程调用不属于这个线程的方法。
不过CFRunloop是线程安全的。
performSelector
performSelector 方法包含在Runloop中。
该方法会创建一个timer对象,然后在合适的runloop模式中,执行传入的方法。所以这个方法,会将传入的参数进行一个retain操作。然后在执行之前就return了。
PerformSelecter
当调用 NSObject 的 performSelecter:afterDelay: 后,实际上其内部会创建一个 Timer 并添加到当前线程的 RunLoop 中。所以如果当前线程没有 RunLoop,则这个方法会失效。
当调用 performSelector:onThread: 时,实际上其会创建一个 Timer 加到对应的线程去,同样的,如果对应线程没有 RunLoop 该方法也会失效。
在该线程的下一次runloop循环中调用
CFRunLoop 线程安全
runloop中包含的三个对象。
CFRunloopSource
CFRunloopTimer
CFRunloopObserver
一个 RunLoop 包含若干个 Mode,每个 Mode 又包含若干个 Source/Timer/Observer。每次调用 RunLoop 的主函数时,只能指定其中一个 Mode,这个Mode被称作 CurrentMode。如果需要切换 Mode,只能退出 Loop,再重新指定一个 Mode 进入。这样做主要是为了分隔开不同组的 Source/Timer/Observer,让其互不影响。
如果一个 mode 中一个 item 都没有,则 RunLoop 会直接退出,不进入循环。
能够主动为runloop添加观察者,不过需要使用cfrunloop中的API.需要先得到cfrunloop,属于core foundation框架中。
core foundation 是用c语言写的一套框架,foundation与cf之间能够通过桥接进行类型转换。cf框架对象中的生命周期不受arc管理,需要开发者自己管理,主动进行retain和release操作。
如果你添加了一个port在多种模式下,如果需要移除,则分别从多个模式下独立移除
如果需要实现回调,需要先创建上述的某一个对象置于runloop中,然后由runloop 在合适的时间进行回调。
每个添加到runloop中对象,必须设定好运行的模式。每一个运行中的runloop,都具有特定的模式,同时也只处理对应模式的观察者,定时器和源事件。
不过,由于runloop的模式只是简单的一个string类型,所以你可以直接自己定义runloop类型。也可以将你自定义的类型添加到common类型中。
runloop只有在该模式下,有至少一个源或者定时器去处理,才能运行。
sourcees或者timer 能够阻止runloop的退出。
通过runloop处理事件,循环,维持应用不退出。
cfrunloop中提供了管理timer,observer,source的接口
runloop本身是递归的,可以在一个runloop里面再添加一个runloop。
runloop运行事件处理器来响应输入事件,runloop接受两种不同类型的源。Input source ,传递异步事件,一般是来自其余线程或者不同应用的消息。Timer source 传递同步事件,在预定的时间调用或者重复调用。这两种源都使用特定的应用处理来处理事件。
Input source 传递同步事件后,会调用runUntilDate方法,去跳出。Timer source传递事件后,不会造成runloop的退出。
Input source
包含两种source ,Port-based , Custom input source .
一般这两个source的处理是不需要做区别的,它们之间唯一的区别就是,Port-baced 由内核创建提出,而custom 由其余线程创建提出。
当你创建一个source的时候,你需要将它给与你runloop的某一种模式。模式将决定input source 如何被监视。大多数时候,runloop将处在默认模式下,不过你也可以指定自定义模式。
Timer
timer并不是真正的时间机制。就像input source,timer只与指定的模式关联。如果不在对应的模式中,timer并不会工作,直到你把模式切换回允许工作的模式。
你也可以配置timer只执行一次或者重复地。不过定时器不是真正的定时,如果一个定时器设定在某个时间后,隔5秒执行一次,如果定时器错过了一个或者多次的执行,它会为错过的时间执行一次,然后重新进行隔5秒执行。
Observer
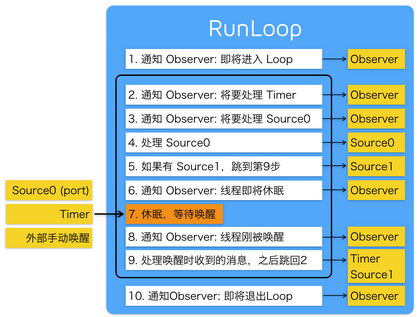
The entrance to the run loop.
When the run loop is about to process a timer.
When the run loop is about to process an input source.
When the run loop is about to go to sleep.
When the run loop has woken up, but before it has processed the event that woke it up.
The exit from the run loop.
Similar to timers, run-loop observers can be used once or repeatedly. A one-shot observer removes itself from the run loop after it fires, while a repeating observer remains attached
观察者只能在core foundation中创建,而不是cocoa 应用
Runloop events
Notify observers that the run loop has been entered.
Notify observers that any ready timers are about to fire.
Notify observers that any input sources that are not port based are about to fire.
Fire any non-port-based input sources that are ready to fire.
If a port-based input source is ready and waiting to fire, process the event immediately. Go to step 9.
Notify observers that the thread is about to sleep.
Put the thread to sleep until one of the following events occurs:
An event arrives for a port-based input source.
A timer fires.
The timeout value set for the run loop expires.
The run loop is explicitly woken up.
Notify observers that the thread just woke up.
Process the pending event.
If a user-defined timer fired, process the timer event and restart the loop. Go to step 2.
If an input source fired, deliver the event.
If the run loop was explicitly woken up but has not yet timed out, restart the loop. Go to step 2.
Notify observers that the run loop has exited.
Runloop的应用
1.使用source来与其他线程进行通信
2.在线程中使用定时器
3.在应用中使用performSelector方法
4.保持线程去执行周期任务